-
Running Angular tests in headless Chrome
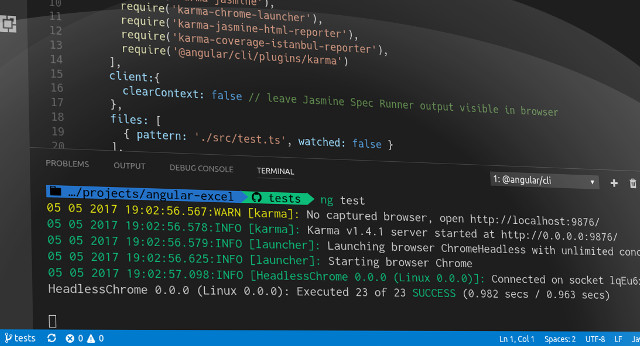
Angular has some great tooling for running tests, namely Karma and Protractor. By default (at least when using Angular CLI) they run using Chrome. So when you execute the tests from command-line, it will pop open a browser window where the tests execute. This works well enough, but sometimes you either don’t want to see that browser window pop open or you are running the tests in an environment where there is no graphical environment (on a CI server or a Docker container for example).
There is nothing new in running Karma tests without a browser window, you have been able to do it with PhantomJS by installing the
karma-phantomjs-launcher. PhantomJS has been good enough solution for this, but you might encounter some issues every now and then and need to add some additional polyfills etc. But Chrome now has the ability to run in headless mode since version 59, so you can use it to run tests without needing to install any additional packages and with a more standard environment. -
Using RxJS Observables with AngularJS 1

Reactive programming with RxJS has become quite popular lately in the frontend world, partly because it is included in Angular 2 and many people have already started learning it even though a stable version is not out yet. But if you are currently working with Angular 1, you don’t have to wait until you start using Angular 2 in your production apps to start using RxJS, since RxJS itself is stable and can be used with any framework.
Whether you already know RxJS and the reactive programming concepts, or just want to learn more about them before you start using Angular 2 for real, this post will show how you can integrate RxJS with Angular 1 and get into reactive programming right now.
-
Building a Deploy Button
I recently got a Olimex A20-OLinuXino-LIME mini computer as a speaker gift for speaking at the Bulgaria PHP Conference. It’s quite similar to a Raspberry Pi, it has few USB ports, Ethernet port, HDMI output and some GPIO pins to hook up some electronics. Quite a lot of GPIO pins actually, a lot more than on Raspberry Pi. And it runs Debian Linux from an SD card. So it’s perfect for doing some hardware hacking and I have been building something on it last week.
I decided to build a deploy button for a project I’m working on at work.
-
Bulgaria PHP Conference 2015 & the PHP Community

A week ago I attended the first Bulgaria PHP Conference that was organized on September 26th and 27th 2015 in Sofia. Even though it was the first PHP conference in Bulgaria, the event was a real success. The venue was spectacular, the atmosphere was laid-back but still enthusiastic and energetic and the speaker line-up was very impressive.
-
What is Clean Code and why should you care?
Clean code is something that I have been interested in for a while now, and plan to write a series of blog posts about the different concepts related to clean code. In this introduction post to the series I will talk a little bit about what clean code actually is and also try to answer the question why should you care about clean code.
-
CQRS? Or did you mean (bumper) cars? – My PHPBenelux 2014 experience
 I recently attended the PHPBenelux 2014 conference with a co-worker of mine. It was the 5th anniversary edition of PHPBenelux and the second time I attended the conference. It was held January 24th & 25th at hotel Ter Elst in Antwerp, Belgium.
I recently attended the PHPBenelux 2014 conference with a co-worker of mine. It was the 5th anniversary edition of PHPBenelux and the second time I attended the conference. It was held January 24th & 25th at hotel Ter Elst in Antwerp, Belgium.In this post I will recap my experience at the conference and highlight what I found most interesting, fun or otherwise noteworthy.
-
What's new in PHP 5.5
So, why another “PHP 5.5 new features” post? I was doing research on the subject for a tutorial at work so I was digging through all the resources I could find on the subject anyway, so I decided to write a post about it. And also because even though there are many great posts already on this topic, I found that none of them were that comprehensive to list all interesting changes that come with PHP 5.5. The PHP manual also has a quite comprehensive documentation about everything that has changed with PHP 5.5 here, but it is scattered across many pages with some not so relevant information (for most PHP devs) in there also. The official ChangeLog also lists everything that has changed, but it obviously does not go into that much detail on any of the topics.
-
Installing SonarQube with Jenkins integration for a PHP project
In this second part of my Continous Integration setup I will detail the steps required to install SonarQube (previously called just Sonar, renamed to SonarQube with 3.6 release just a few days ago) and integrate it with the Jenkins server from the previous post so SonarQube will run a daily analysis of our PHP project. In the previous post I covered the installation of Jenkins on a CentOS server and integrated it with GitHub, so if you do not have Jenkins set up you might want to start there.
-
Installing Jenkins CI server with GitHub integration for a PHP project
Here are the details how to install Jenkins CI server on a CentOS server (version 6.4 in this case) and set it up with GitHub integration so pushing to GitHub automatically triggers a build. Our project is a PHP project so the build will have PHP related stuff and we are going to use Ant as the build system.
-
Validating data with triggers in MySQL
MySQL triggers can be used to create some validation conditions that are a little bit more complex than what can be achieved with basic data types and unique index for example. The reason why data validation is better kept at the database level rather than application level is that in case the same data source is used by multiple applications, or even multiple interfaces within the same application, is that you can rely on the data being consistent and valid regardless the validation logic on the application side, which might not always be consistent across different implementations.
See older posts in the Posts Archive.
Subscribe via RSS